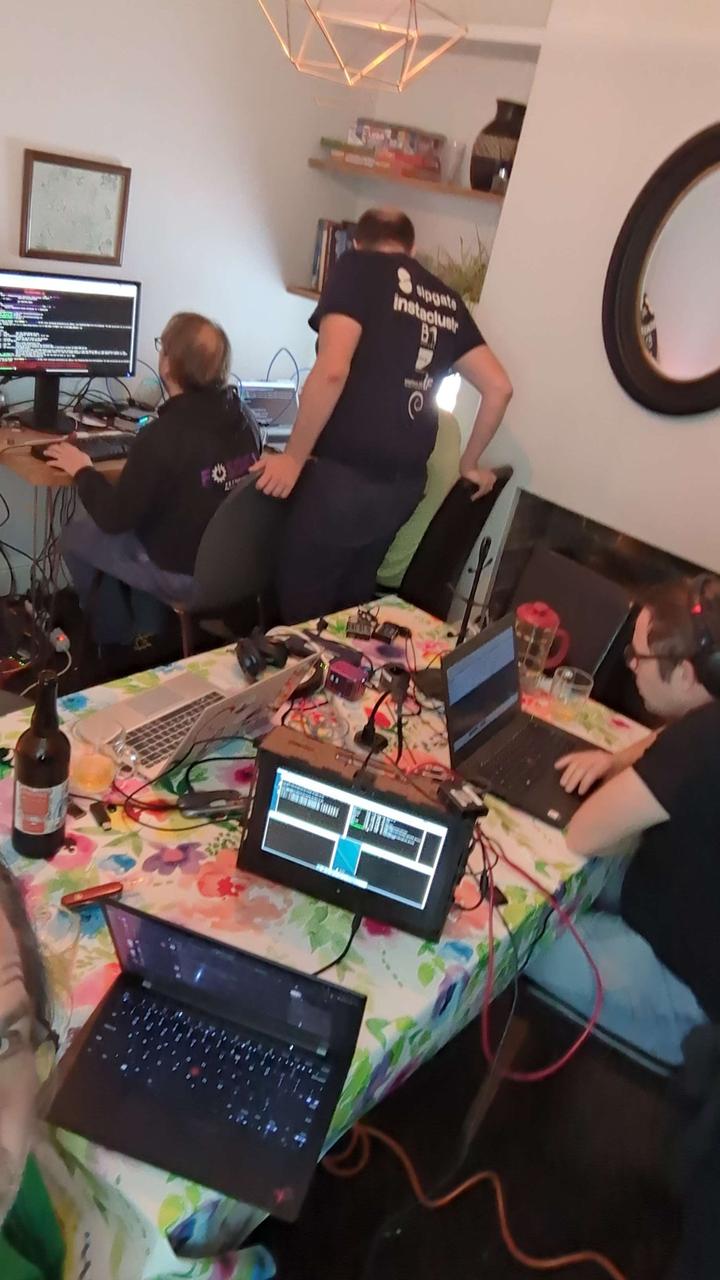
This week, some of the DebConf Video Team
met in Herefordshire (UK) for a
sprint. We didn't have
a sprint in 2024, and it was sorely needed, now.
At the sprint we made good progress towards using Voctomix 2 more
reliably, and made plans for our future hardware needs.
Attendees
- Chris Boot (host)
- Stefano Rivera
- Kyle Robbertze
- Carl Karsten
- Nicolas Dandrimont
Voctomix 2
DebConf 25 was the first event that
the team used Voctomix version 2.
Testing it during DebCamp 25 (the week before DebConf), it seemed to
work reliably. But during the event, we hit repeated audio dropout
issues, that affected about
18 of our recordings (and live streams).
We had attempted to use Voctomix 2 at DebConf 24, and quickly rolled
back to version 1, on day 1 of the conference, when we hit similar
issues. We thought these issues would be resolved for DebConf 25, by
using more powerful (newer) mixing machines.
Trying to get to the bottom of these issues was the main focus of the
sprint. Nicolas brought 2 of Debian's cameras and the Framework laptop
that we'd used at the conference, so we could reproduce the problem.
It didn't take long to reproduce, in fact, we spent most of the week
trying any configuration changes we could think of to avoid it.
The issue we've been seeing feels like a gstreamer bug, rather than
something voctomix is doing incorrectly. If anything, configuration
changes are avoiding hitting it.
Finally, on the last night of the sprint, we managed to run voctomix all
night without the problem appearing. But... that isn't enough to feel
confident that the issue is avoided. More testing will be required.
Detecting audio breakage
Kyle worked on a way to report the audio quality in our Prometheus
exporter, so we can automatically detect this kind of audio breakage.
This was implemented in
helios our audio
level monitor, and lead to some related code refactoring.
Framework Laptops
Historically, the video team has relied on borrowed and rented computer
hardware at conferences for our (software) video mixing, streaming,
storage and encoding. Many years ago, we'd even typically have a local
Debian mirror and upload queue on site.
Our video mixing machines had to be desktop size computers with 2
Blackmagic Declink Mini
Recorder PCI-e
cards installed in them, to capture video from our cameras.
Now that we reliably have more Internet bandwidth than we really need,
at our conference venues, we can rely on offsite cloud servers. We only
need the video capture and mixing machines on site.
Blackmagic also has UltraStudio
Recorder
thunderbolt capture boxes that we can use with a laptop.
The project bought a couple of these and a Framework 13
AMD laptop to test at DebConf 25.
We used it in production at DebConf, in the "Petit Amphi" room, where it
seemed to work fairly well. It was very picky about thunderbolt cable
and port combinations, refusing to even boot when they were connected.
Since then, Framework firmware has fixed these issues, and in our
testing at the sprint, it worked almost perfectly. (One of the capture boxes
got into a broken
state,
and had to be unplugged and re-connected to fix it.)
We think these are the best option for the future, and plan to ask the
project to buy some more of them.
HDCP
Apple Silicon devices seem to like to HDCP-encrypt their HDMI output
whenever possible. This causes our HDMI capture hardware to display an
"Encrypted" error, rather than any useful image.
Chris experimented with a few different devices to strip HDCP from HDMI
video, at least 2 of them worked.
Spring Cleaning
Kyle dug through the open issues in our Salsa
repositories and cleaned
up some issues.
DebConf 25 Video Encoding
The core video team at DebConf 25 was a little under-staffed,
significantly overlapping with core conference organization, which
took priority.
That, combined with the Voctomix 2 audio dropout issues we'd hit, meant
that there was quite a bit of work left to be done to get the conference
videos properly encoded and released.
We found that the encodings had been done at the wrong resolution, which
forced a re-encode of all videos. In the process, we reviewed videos for
audio issues and made a list of the
ones
that need more work. We ran out of time and this work isn't done,
yet.
DebConf 26 Preparation
Kyle reviewed floorplans and photographs of the proposed DebConf
26 talk venues, and build up a list of A/V kit
that we'll need to hire.
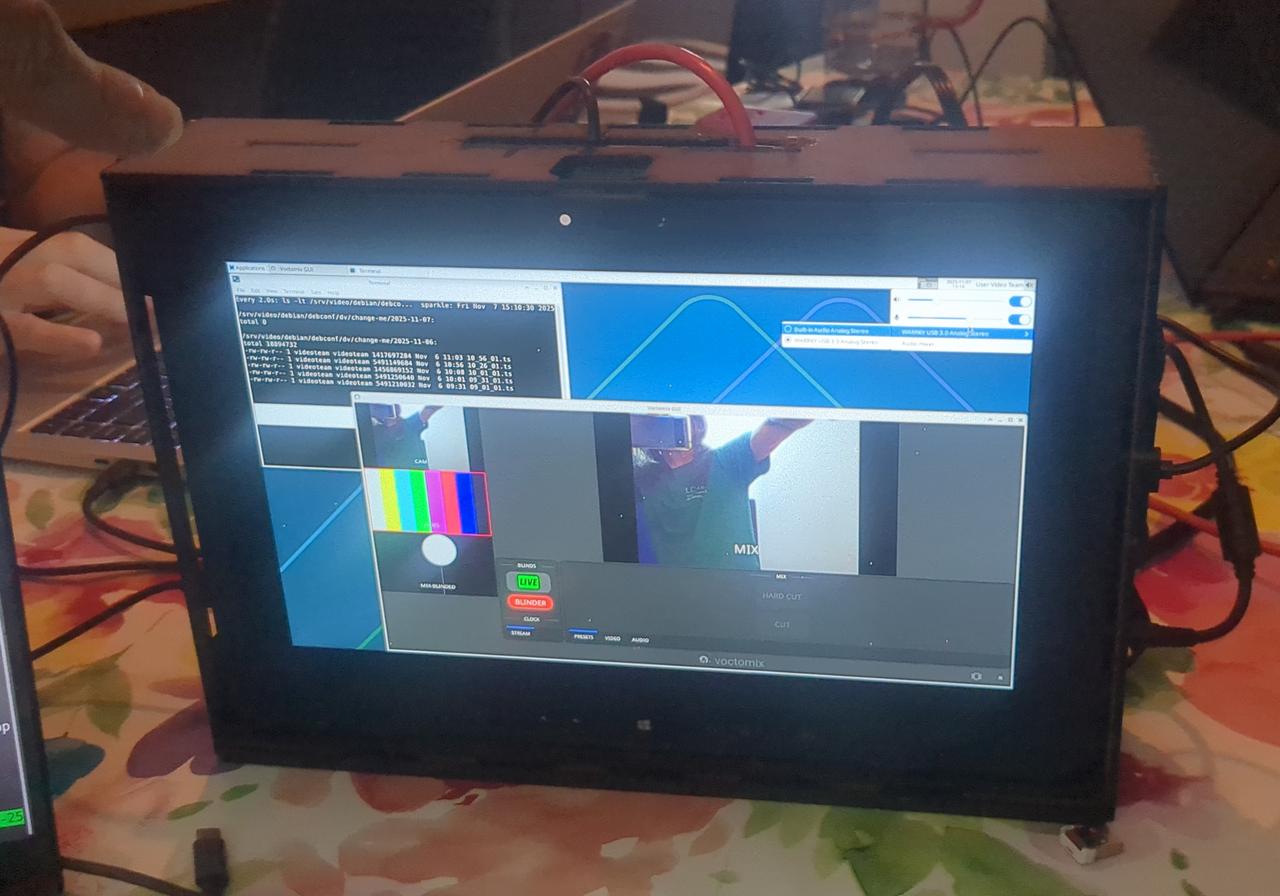
Carl's Video Box
Carl uses much of the same stack as the video team, for many other
events in the US. He has experimenting with
using a Dell 7212 tablet in an all-in-one laser-cut box.
Carl demonstrated this box, which could perfect for small miniDebConfs,
at the sprint. Using voctomix 2 on the box requires some work, because
it doesn't use Blackmagic cards for video capture.

gst-fallbacksrc
Carl's box's needs lead to looking at
gstfallbacksrc.
This should let Voctomix 2 survive cameras (or network sources) going
away for a moment.
Matthias Geiger packaged it for us,
and it's now in Debian NEW. Thanks!
voctomix-outcasts
Carl cut a release of
voctomix-outcasts and
Stefano uploaded it to unstable.
Ansible Configuration
The videoteam's stack is deployed with Ansible, and almost everything we
do involves work on this stack. Carl upstreamed some of his features to
us, and we updated our voctomix2 configuration to take
advantage
of our experiments at the sprint.
Miscellaneous Voctomix contributions
We fixed a couple of minor
bugs in voctomix.
More Nageru experimentation
In 2023, we tried to configure Nageru
(another live video mixer) for the video team's needs. Like voctomix
it needs some configuration and scaffolding to adapt it to your needs.
Practically, this means writing a "theme" in Lua that controls the
mixer.
The team still has a preference for Voctomix (as we're all very familiar
with it), but would like to have Nageru available as an option when we
need it. We
fixed
some minor issues in our theme, enough to get it running again, on the
Framework laptop. Much more work is needed to really make it a useable
option.
Thank you
Thanks to the Debian project for funding the costs of the sprint, and
Chris Boot's extended family for providing us with a no-cost sprint
venue.
Thanks to c3voc for developing and maintaining
voctomix, and helping us to debug issues in it.
Thank you to everyone in the videoteam who attended or helped out
remotely! And to employers who let us work on Debian on company time.
We'll likely need to keep working on our stack remotely, in the leadup
to DebConf 26, and/or have another sprint before then.